

How to use XPath: a beginner SEO’s guide
XPath is one of those things I learned out of pure, unabashed hatred for data entry. There are few things more boring than clicking through a spreadsheet full of URLs in column A just to copy and paste their date published into column B.
That’s where XPath queries come in handy.
XPath is the language we use to navigate to specific parts of an XML document, and with a single XPath query and the scraping tool of our choice (we like Screaming Frog and Google Sheets’ IMPORTXML for scraping), we can grab information off of dozens of pages at once without ever having to do the copy/paste dance that makes us wither away in our office chairs.
In this article, I’ll teach you a few XPath queries and how to use them for scraping webpage elements for SEO, and then I’ll teach you some XPath syntax to write your own.
XPath Cheat Sheet
Before we begin creating some of our own XPath queries for different pages, here’s a list of queries that can be used on any site.
| XPath Query | Outcome |
//h1 | Scrapes all h1s |
//title | Scrapes all titles |
//meta[@name='description']/@content | Scrapes the meta description |
//@href | Scrapes all links |
//link[@rel=’canonical’]/@href | Scrapes any canonicals |
//*[@itemtype]/@itemtype | Scrapes types of schema |
//*[@hreflang] | Scrapes hreflang |
For pulling these elements off of a bunch of pages, I’ve outlined two tools below:
Scraping with XPath Method 1: Using Google Sheets’ =IMPORTXML
1. Here’s my Google Sheets document for scraping data off of different pages. I’ve put the list of the URLs I want to scrape from in Column A:

2. In column B, I’m going to use the function on each URL listed in Column A:
=IMPORTXML(URL, XPath query)
IMPORTXML takes two parameters:
- URL: the URL you want to pull the data from OR the cell name that contains the URL
- XPath query: the XPath query you’d like to use.

For this example, our function looks like this:
=IMPORTXML(A3, “//title”)
Note the quotations marks! You’ll know it’s formatted properly when the XPath query turns green.
Press enter, and you’ve got yourself a page title!
3. Copy & paste the formula along Column B by highlighting the cell with the formula, and double clicking on the little square in the bottom right corner.

That’s it, you’re done!

* A few notes on using =ImportXML. ImportXML is best used when:
- You’re working with a smaller sized set of pages. After using ImportXML about 50 times on one sheet, you start to get “loading” errors that never resolve themselves.
- The data you’re planning to pull hasn’t been modified by Javascript.
Often times if I can’t get ImportXML to work, and my XPath query checks out in the DevTools bar on Chrome (Mac: Command + Option + I → Command + F to open up the search bar), I’ll use Screaming Frog’s custom extraction instead.
Scraping with XPath Method 2: Screaming Frog Custom Extraction
Screaming Frog is an extremely robust site crawling tool that we use at Brainlabs. At its default, Screaming Frog will already give you the title, h1, meta description, canonicals, internal links, status codes, etc. For scraping other parts of a page, it has a handy tool called Custom Extraction. Here’s how to use it.
1. In the Screaming Frog toolbar, click on Configuration > Custom > Extraction.

This custom extraction window should pop up:
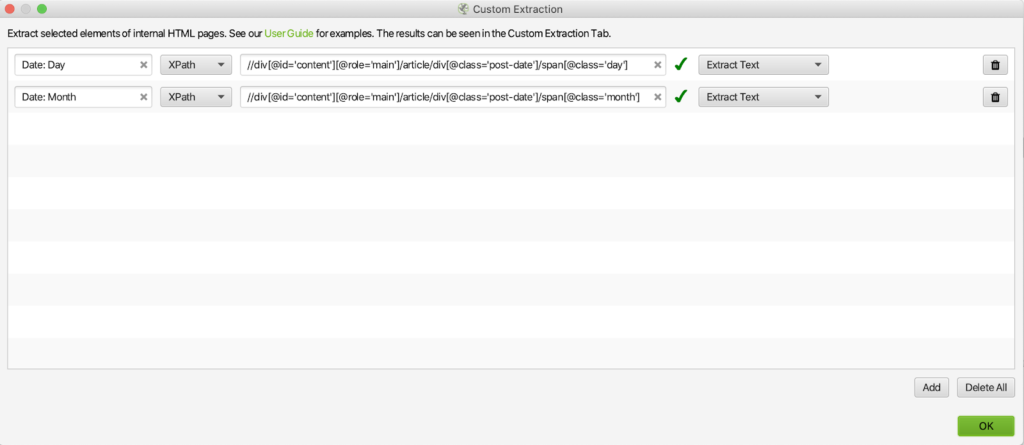
2. Click Add, and fill in the boxes with the name of your extractor and your XPath query. Make sure to set the dropdown box to XPath!
For the purposes of this example, I’ll be pulling the dates off of five Brainlabs blog posts, so for the second dropdown box, I’ll want to use either “Extract Text” (which pulls only the text content of the selected element) or “Extract Inner HTML” (which pulls everything inside the element that we’re selecting, including other HTML elements).

You can use Custom Extraction for other things that we won’t cover in this article, so I’ve linked to Screaming Frog’s Custom Extraction guide here.
Click OK.

3. Now we want to tell Screaming Frog which URLs to crawl. Go back to the toolbar and click Mode > List. This allows us to crawl specific pages rather than entire sites.

4. Click Upload > Enter Manually. (If you have a file of all your URLs, you can use From a File instead)

5. Copy and paste your URLs into the box, and follow the prompts on the URL List window. Screaming Frog should start crawling automatically!

6. When Screaming Frog is finished crawling, in the main window, scroll all the way over to the right to see your Custom Extraction, or click on the Custom Extraction Tab within the Screaming Frog window.

7. Click Export, and that’s it! You’ve got your very own list of custom extracted dates!
So you have your cheat sheet of XPath queries and a few ways to use them at scale. What if you want to create your own Xpath query? In order to do this, you’ll need to know a few symbols that help string together the parts on an HTML document.
Path Expressions: / and //
Here’s an HTML page with Google’s DevTools opened up (on Mac: COMMAND+OPTION+I)

HTML pages are made up of element nodes. Notice how nodes are nestled inside the nodes above them:

The <p> node and the <h1> node is nestled inside the <body> node, which is inside the <html> node. This is important to note since writing out XPath is usually a matter of writing out the nodes in order of “biggest to smallest”.
Let’s say we wanted to collect the stuff inside the <p> node. There are a few ways we could write our XPath query out.
I like to start by opening up Google’s DevTools (mac: COMMAND+OPTION+I) on the page with the search panel open (mac: COMMAND+F) to test out potential XPath queries.

Typing out your XPath in the search bar lets you check your work because when your XPath query is correct, it’ll highlight the element (or elements) that the XPath points to in the source code.
In this example, there are many different ways to get to the same <p> node. For now, we can use / and // to accomplish our goal.
1. /
If used at the beginning of the expression, / establishes the root node or the biggest node in the document. Since we’re using XPath for HTML, the root node will always be /html
When / is used after the root node, it signals the start of the node that is nestled directly inside of the node before it. So for our example, using just / to create our XPath query would look like this:
/html/body/p
What the above query is asking is to find the <p> node, which is inside the <body> node, which is inside the <html> node. And don’t go skipping nodes!
❌ Don’t: /html/p
We won’t be able to find our <p> node if we don’t look through the <body> node first.
❌ Don’t: /html/body/h1/p
Although the <p> node comes after the <h1> node, the <p> node isn’t nestled inside of the <h1> node.
2. //
// allows you to “cheat” and start the expression at any node. // pulls ALL of the elements of that node name, no matter where they are in the document
To find the <p> node in our example, it could look like this:
//p
Or this:
//body/p
3. Google Chrome Copy XPath
Google Chrome has a handy feature that copies an element’s XPath.
In Chrome, highlight the element whose XPath you’d like to copy:

Right click the highlighted element > Inspect. This brings up Chrome’s DevTools.
Right click on the element within DevTools > Copy > Copy XPath.

And Paste! Here’s what it should look like:
/html/body/p
This is the XPath query for your highlighted element, written out node by node. This is a quick and easy method to find an element’s XPath as long as you only want one element from the page.
What if the HTML document looked like this, and we wanted to navigate to the second <p> element?

Here are some XPath queries that you could use:
✅ /html/body/div/p
✅ //body/div/p
✅ //div/p
And here are some ways that won’t work:
❌ //p
This will pull both <p> nodes.
❌ //body/p
This will pull only the p tag that is DIRECTLY within the body. It will not pull the p that is also within the <div> node.
❌ //body//p
This will pull both <p> tags.
Now that we’ve practiced // and / expressions, let’s move on to some additional expressions that help refine your XPath queries.
More XPath Syntax: @
In the big ol’ internet, HTML code often looks more complex than the above-mentioned examples. For instance, here’s the first bit of HTML that makes up Brainlabs’ homepage:

With a page like this, you wouldn’t get any valuable information out of pulling things out by the element node name alone. There are just too many divs on the page. That’s where attributes come in.
You’ll notice that there are some elements that have “accessories” attached to the node name:

This div has a class ”imp-tooltips-container” and a data-imp-tooltips-container “6989”.
And this <a> has an href “https://www.brainlabsdigital.com/services/".

These are called attributes, and they’re the secret ingredient to making a good XPath query. With them, we can specify which elements we want to select by pulling them with “@”.
Here’s how we can use @, along with some examples of XPath queries in context (for this example, I’m scraping a Brainlabs blog post).

@attribute
selects the value of the attribute
Example: //a/@href
This xpath query is asking to pull every href attribute within all <a> nodes.
It won’t, however, pull the anchor text within the <a> nodes. For that, you would use //a.
💡 Tip! To easily find your element of interest’s source code, right click the content directly on the webpage, and click inspect. Chrome DevTools should pop up, with the element highlighted in the source code.

XPath Syntax Lightning Round
Here are a few more expressions you can add on to your XPath query. For this example, I’m using this Brainlabs blog post to show you how these expressions can be used.

1. [1]
This selects the first of multiple elements:
Example. //figure[1]/img/@alt
Pulls the first image’s alt text.
2. contains(@attribute, ‘text’)
This selects every node with an attribute that partially matches the text provided:
Example. //ul[@id='menu-main-menu']/li[contains(@id, 'nav-menu-item')]//a/@href
In Brainlabs’ navigation menu, all the menu options have an id ‘nav-menu-item-####’ with a different 4 digit number at the end. We can pull all the menu options by using contains(@id, ‘nav-menu-item’) which will ignore the 4 digit number at the end of the menu option id.
3. |
This selects multiple elements:
Example. //figure[1]/img/@src | //figure[1]/img/@alt
Pulls the image source file AND the alt text
And here’s what a Screaming Frog export looks like when you plug in these XPath queries into the Custom Extraction tool (I reformatted on Google Sheets first):

Conclusion & Further Readings
There are many more ways to customize your XPath query, like adding functions, using true/false operators, and wildcards. For further reading, I recommend W3School’s guide and librarycarpentry’s Introduction to Webscraping to become a true XPath master.
That’s all I’ve got for you today! I hope this guide helped you learn the basics for using XPath to scrape data, and I hope you never have to manually record data ever again.


