

Understanding crawl budget with log file analysis
Log file analysis is one of those tasks you might not do often – due to data availability & time constraints – but that can provide insights you wouldn’t be able to discover otherwise, particularly for large sites. If you’ve never done a log analysis or are unsure what exactly to look for and where to start, I’ve built a guideline to help you:
- Get started with some log file analysis tools
- Understand what log files are useful for
- Digging into the data and think how to better redistribute crawling resources
Log files are essentially a diary of all requests made to your site for a specific time period. The data is very specific and more in depth than you could gather from a crawl, Google Analytics and Google Search Console combined. By analysing this data you can quantify the size of any potential issue you discover and make better decisions on what to dig into even further. You can also discover issues things such as weird crawlers behavior which you could not identify through a regular tech audit. Log analysis is particularly valuable for large sites where a crawl would require an extensive amount of time and resources.
Log file analysis tools
There are different tools out there for this task, Screaming Frog, Botify and BigQuery to mention a few. We use BigQuery, which is quite flexible. A great place to get started if you’re not familiar with log analysis is the guideline my colleague Dom Woodman wrote on what a log file analysis is and how to do.
Regardless of the tool you choose to use, you should be able to use the framework below.
Understand what log files are useful for
Log files are a really good source for:
- Discovering potential problems: use them to find things you can’t with a crawl since that doesn’t include historical memory of Google
- Identify what to prioritise: knowing how often Google visits URLs can be a useful way of prioritising things.
The best part about log files is that they include all kinds of information you might want to know about, and more. Page response code? They have it. Page file type? Included. Crawler type? Should be in there. You get the idea. But until you slice your data in meaningful ways you won’t know what all this information is useful for.
Digging into the data
When you begin to analyse logs, you should slice the information in big chunks to obtain a good overall picture of the data because it helps to understand what to prioritise. You should always compare results to the number of organic sessions obtained because it helps to establish if crawling budget should be distributed differently.
These are the criteria I use to dig into the log file:
- Top 10 URLs/paths most requested
- 200-code vs. non 200-code page
- URLs with parameters vs non parameters
- File type requests
- Requests per subdomain
Before you begin
At this stage, you should also decide on a threshold for what represents a significant percentage of your data. For example, if you discover that there are 20,000 requests with a 301 response code and the total number of requests on the logs are 2,000,000, then knowing that the 301s are only 1% of total requests helps you bucket this as a low priority issue. This might change by type, for example, 10% of category pages with a 404 status code might be more important than 10% of product pages with a 404 code.
Once you begin obtaining results from your data, you should consider whether the current crawler behavior is the best use of crawling resources. The answer to this question will tell you what the following actions should be.
Top 10 URLs/paths most requested vs organic sessions they drive
Through log file analysis you’ll often discover a few paths or specific URLs that had a significantly higher amount of requests compared to the rest. These usually happen to be URLs linked from most templates, for example from main nav or footer, or from external sources but don’t often drive a high number of organic sessions.
Depending on what type of URLs these are, you may or may not need to take action. For example, if 40% of resources are used to request a specific URL, is that the best use of crawling resources or could they be better distributed?
Below is an example of the breakdown of top requested paths from log analysis and how they compare to organic sessions they drive:
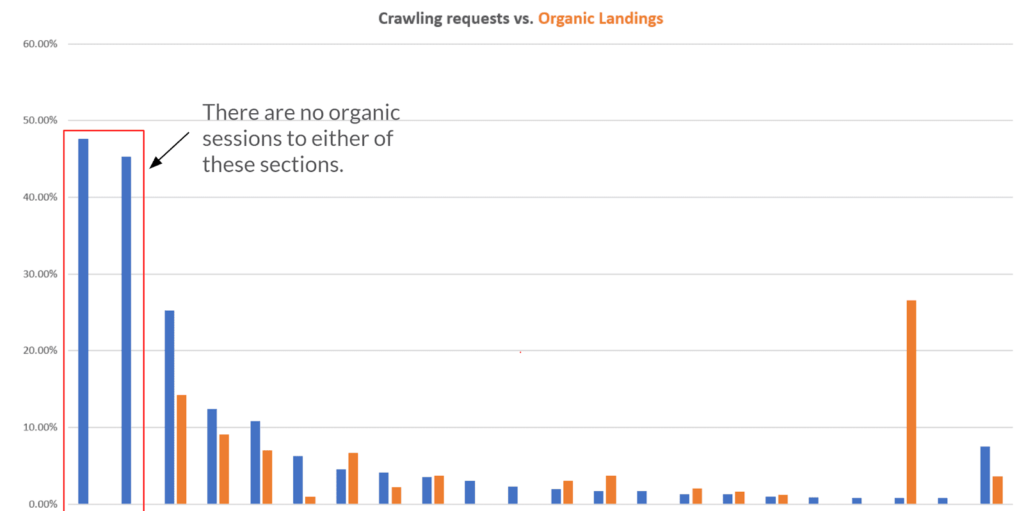
Making this comparison on a graph allows you to easily identify how crawling resources could be better distributed. The first two blue bars show that the majority of requests are to two specific paths which drive no organic sessions. This is a quick way to identify important wins right away: in the example above, the next step would be to understand what those URLs are and where they are found to then decide whether they should be crawled and indexed or what additional action may be required. A tech audit would not give you the information I show in the graph.
Page response code
Based on whether a high percentage of the log requests is a non-200 code page, you may want to dig into this area further. Here you should query your data to discover what is the break down of non-200 code page and based on results dig further, prioritising those with the highest percentage.
Below is an example of non-200 code pages breakdown:
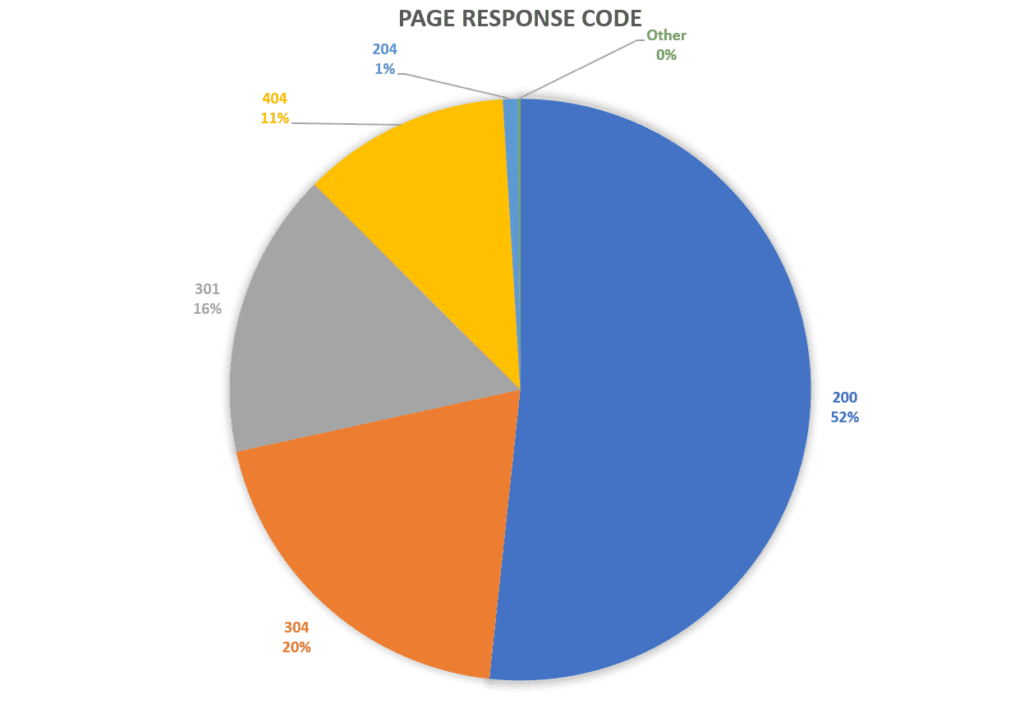
As visible above, almost 50% of all requests are to a non-200 status code page. In this case, investigate further into each status code to discover which type of pages they come from and what percentage each represents. As a side note, if you also encounter a large number of pages with a 304 status code, this is a server response essentially equivalent to a 200-status code. The 304 response indicates that the page has not changed since the previous transmission.
Here are some common checks you should do on non-200 code pages:
- Are there patterns of internal links pointing to these pages? A crawl of the site would be able to answer this.
- Is there a high number of external links/domains pointing to these pages?
- Are any of these pages’ status code caused by certain actions/situations? (i.e. on ecommerce sites, discontinued products may become 404 pages or 301 redirects to main categories)
- Does the number of pages with a specific status code change over time?
URLs with parameters vs non-parameters
URLs with parameters can cause page duplication, in fact very often they are just a copy of the page without parameters, creating a large number of URLs that add no value to the site. In an ideal world, all URLs discovered by crawlers do not include parameters. However, this is not usually the case and a good amount of crawling resources are used to crawl parameterised URLs. You should always check what percentage of total requests parameterised URLs make up for.
Once you know the size of the issue, here are a few things to consider:
- What is the page response code of these URLs?
- How are parameterised URLs being discovered by crawlers?
- Are there internal links to parameterised URLs?
- What parameter keys are the most found and what are their purpose?
Depending on what you discover in this phase, there may be actions related to previous steps that apply here.
File type requests
I always check the file type breakdown to quickly discover whether requests to resources such as images or JavaScript files make up a big portion. This should not be the case and in an ideal scenario as the highest percentage of requests should be for HTML type of pages because these are the pages Google not only understands but are also the pages you want to rank well. If you discover that crawlers are spending considerable resources for non-HTML files, then this is an area to dig into further.
Here are a few important things to investigate:
- Where are the resources discovered/linked from?
- Do they need to be crawled or should they just be used to load the content?
As usual, you should bear in mind the most important question: is this the best use of crawling resources? If not, then consider blocking crawlers from accessing these resources with an indexing purpose. This can be easily done by blocking them on robots.txt, however, before you do you should always check with your dev.
Requests per subdomain
You may not need this step if you don’t have any subdomains, but otherwise, this is a check you should do to discover unusual behavior. Particularly, if you are analysing the logs of a specific domain, requests to other domains should be somewhat limited, depending on how your internal linking is organised. It also depends if Google sees the subdomains as your site rather than a separate subdomain.
As with the previous steps, this is the first breakdown of your data and based on the results it should tell you whether anything is worth digging further into or not.
A few things to keep in mind in this section:
- Should crawler spend less/more time on subdomains?
- Where are the subdomain pages discovered within your site?
This could be another opportunity for redistributing crawling budget to the pages you want crawlers to discover.
To wrap it up
As with many SEO tasks, there are many different ways to go about a log analysis. The guideline I shared is meant to provide you with an organised method that helps you think about crawling budget resources and how to better use them.


